
* ISA는 Instruction Set Architecture, 즉 명령어 집합 구조이며, 마이크로프로세서가 인식해서 기능을 이해하고 실행할 수 있는 기계어 명령어를 말한다.
기계어
기계어는 컴퓨터가 직접 읽을 수 있는 2진 숫자(0과 1)로만 이루어져있다. (+ 16진숫자도 사용함)
우리가 열심히 작성하는 코드들은 사실 컴퓨터가 있는 그대로 알아듣질 못 한다. 0과 1로 번역해주는 번역가가 필요하다.
번역가는 두 종류가 있는데, 컴파일러(Compiler)와 인터프리터(Interpreter)다.
이 두 친구에 대해 더 잘 알고 싶다면
2022.12.02 - [📂 CS Knowledge/CS Knowledge] - [CS] 동적 언어와 정적 언어
[CS] 동적 언어와 정적 언어
어떤 언어든, 언어를 배울 때 가장 먼저 배우는 것이 무엇일까? 바로 자료형(type)이다. 이런 자료형이 언제 결정되느냐에 따라 동적 언어인지 정적 언어인지로 나뉘는데, 이번 포스팅에서 알아보
jyostudy.tistory.com
이 글을 참고해주시길! 💡
어셈블리어
분명 명령어에 대한 포스팅인데 왜 기계어에 대한 이야기만 줄줄 하고있는지..?!!!
바로바로 어셈블리어를 얘기하기 위한 빌드업이었다.
어셈블리어란 기계어를 사람도 읽기 편한 형태로 번역한 언어다.

대충 이런식으로 생겼는데, 중간에 우리도 알아들을 수 있을만한 push, and, ret 같은 것들이 보인다.
저 한줄한줄이 무엇을 의미하는지는 지금 당장 몰라도 된다. 저 한줄 한줄이 명령어라는 것만 알면 된다.
명령어
그렇다면 명령어는 어떻게 구성되어 있을까?
이해하기 위해 먼저 명령이란 것에 대해 생각해보자.
나는 본가에 있을 때 주로 내 손으로 불을 끄지 않고 무조건 동생을 시킨다
"홍아!!! 불 좀 꺼줘!!!!"
하면 사랑스런 내 동생이 와서 불을 꺼주고 간다.
위의 명령어는 '홍'에게 '불'을 '끌' 것을 명령하는 말이다.
컴퓨터의 명령어도 똑같다.
무엇을 가지고 어떤 작동을 수행하는지가 주 내용이 된다.
연산 코드와 오퍼랜드
명령어는 연산 코드와 오퍼랜드로 구성되어 있다.

연산코드는 명령어가 수행할 연산이며 크게 네 종류로 나뉜다.
1. 데이터 전송 : MOVE, STORE, LOAD(FETCH), PUSH, POP
2. 산술/논리연산 : ADD/SUBSTRACT/MULTIPLY/DIVIDE, INCREMENT/DECREMENT, AND/OR/NOT, COMPARE
3. 제어 흐름 변경 : JUMP, CONDITIONAL JUMP, HALT, CALL, RETURN
4. 입출력 제어 : READ(INPUT), WRITE(OUTPUT), START IO, TEST IO
오퍼랜드는 '데이터' 또는 '데이터가 저장된 위치'가 들어갈 수 있다.
대부분의 경우에는 데이터 그 자체보다는 데이터가 저장된 위치를 오퍼랜드에 담아두기 때문에 오퍼랜드 필드를 주소 필드라고 부르기도 한다.
오퍼랜드는 명령어 안에 하나도 없을 수도 있고, 한 개만 있을 수도 있고, 두 개 또는 세 개 등 여러개가 있을 수도 있다.
오퍼랜드의 개수에 따라 0-주소 명령어/1-주소 명령어/2-주소 명령어/3-주소 명령어라고 칭한다.
주소 지정 방식
오퍼랜드 필드에는 주로 메모리나 레지스터의 주소를 담는다.
왜 데이터를 직접 쓰지 않을까? 데이터를 직접 쓰는게 더 편하지 않나?라고 생각할 수 있다.
굳이 주소를 쓰는 이유는 바로 명령어의 길이 제한 때문이다.
하나의 명령어가 16비트고 연산 코드 필드가 4비트인 2-주소 명령어가 있다고 해보자.
연산 코드 필드를 뺀 12비트를 두 개의 오퍼랜드가 나눠가져야하는데, 그럼 다음과 같이 나뉜다.
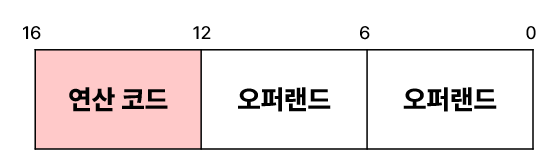
이 경우에는 하나의 오퍼랜드로 표현할 수 있는 정보의 가짓수가 2의 6승, 즉 64개뿐이다.
하지만 만약 오퍼랜드 필드 안에 메모리 주소가 담긴다면 표현할 수 있는 데이터의 크기는 하나의 메모리 주소에 저장할 수 있는 공간만큼 커진다.

한 주소에 16비트를 저장할 수 있는 메모리가 있다면, 그 메모리의 10번지에 데이터를 저장하고 해당 메모리 주소를 명시한다.
이 경우 6비트의 데이터만 담을 수 있던 것이 16비트로 확 커진다.
레지스터 이름을 명시할 때도 마찬가지다. 이 경우에는 표현할 수 있는 정보의 가짓수가 해당 레지스터가 저장할 수 있는 공간만큼 커진다.
이렇게 연산의 대상이 되는 데이터가 실제로 저장되어 있는 위치를 유효 주소라고 한다. 위의 그림같은 경우에는 유효주소가 10번지다.
이렇게 오퍼랜드 필드에 데이터가 저장된 위치를 명시한 경우에, 연산에 사용할 데이터 위치를 찾는 방법을 주소 지정 방식이라고 한다.
CPU는 다양한 주소 지정 방식을 사용한다.
즉시 주소 지정 방식
즉시 주소 지정 방식(immediate addressing mode)은 연산에 사용할 데이터를 오퍼랜드 필드에 직접 명시하는 방법이다.
앞서 설명했던 것처럼 저장 가능한 데이터의 크기는 작아지지만 주소를 통해 이동하는 짓을 하지 않아도 되므로 다른 방식에 비해 빠르다.
직접 주소 지정 방식
직접 주소 지정 방식(direct addressing mode)은 오퍼랜드 필드에 유효 주소를 직접적으로 명시하는 방식이다.
즉시 주소 지정 방식에 비해서 표현할 수 있는 데이터의 범위가 당연히 커진다.
하지만 여전히 한계점이 존재한다.

위의 사진을 다시 가져와봤는데, 이 경우 유효 주소의 길이가 6비트까지만 가능하다.
더 많은 비트를 필요로 하는 주소는 사용할 수 없다.
간접 주소 지정 방식
간접 주소 지정 방식(indirect addressing mode)은 유효 주소의 주소를 오퍼랜드 필드에 명시하여 직접 주소 지정 방식의 한계점을 보완한다.
하지만 오퍼랜드 -> 유효 주소의 주소 -> 유효 주소로 가는 방법으로 두 번의 메모리 접근이 필요하기 때문에 느리다는 단점이 있다.
레지스터 주소 지정 방식
레지스터 주소 지정 방식(register addressing mode)은 직접 주소 지정 방식과 비슷하게 연산에 사용할 데이터를 저장한 레지스터를 오퍼랜드 필드에 직접 명시하는 방법이다.
메모리는 CPU의 외부에 있고, 레지스터는 CPU 내부에 있다. 바깥까지 나가는 것보다 CPU 내부에서 후딱후딱 해치우는게 더 빠르므로 직접 주소 지정 방식에 비해서 빠르다. 하지만 직접 주소 방식의 한계점을 공유한다. 표현할 수 있는 레지스터 크기에 제한이 생긴다는 점이다.
레지스터 간접 주소 지정 방식
레지스터 간접 주소 지정 방식(register indirect addressing mode)은 간접 주소 지정 방식처럼 연산에 사용할 데이터를 메모리에 저장하고, 그 주소(유효 주소)를 저장한 레지스터를 오퍼랜드 필드에 명시하는 방법이다.
오퍼랜드 -> 레지스터에 있는 유효 주소의 주소 -> 메모리에 있는 유효 주소로 가는 방법으로 레지스터 주소 지정방식에 비해서는 느리나 레지스터를 한 번 거친다는 점에서 간접 주소 지정 방식보다는 빠르다.
MIPS-32 ISA
1. CPU는 4byte 크기의 레지스터 32개를 가지고 있고, $[#register]로 표현한다. ($0 ~ $31)

2. 명령어 형식

* OP : Opcode, 명령 종류 구분
* rs, rt : 첫번째, 두번째 source register의 번호
* rd : destination register, 즉 결과를 저장할 레지스터의 번호
* shamt : shift할 값(srl, sll)
* funct : Opcode의 보충, 명령 종류를 구분하는 번호

* OP
* rs : 첫 번째 source register의 번호
* rt : 결과를 저장할 레지스터의 번호
* address : 상수값(두번째 source 인자로 쓰임)

* adress : jump target(점프할 명령어의 주소 / 4)
3. 명령어 요약
