
백준 1260번 DFS와 BFS 파이썬 풀이
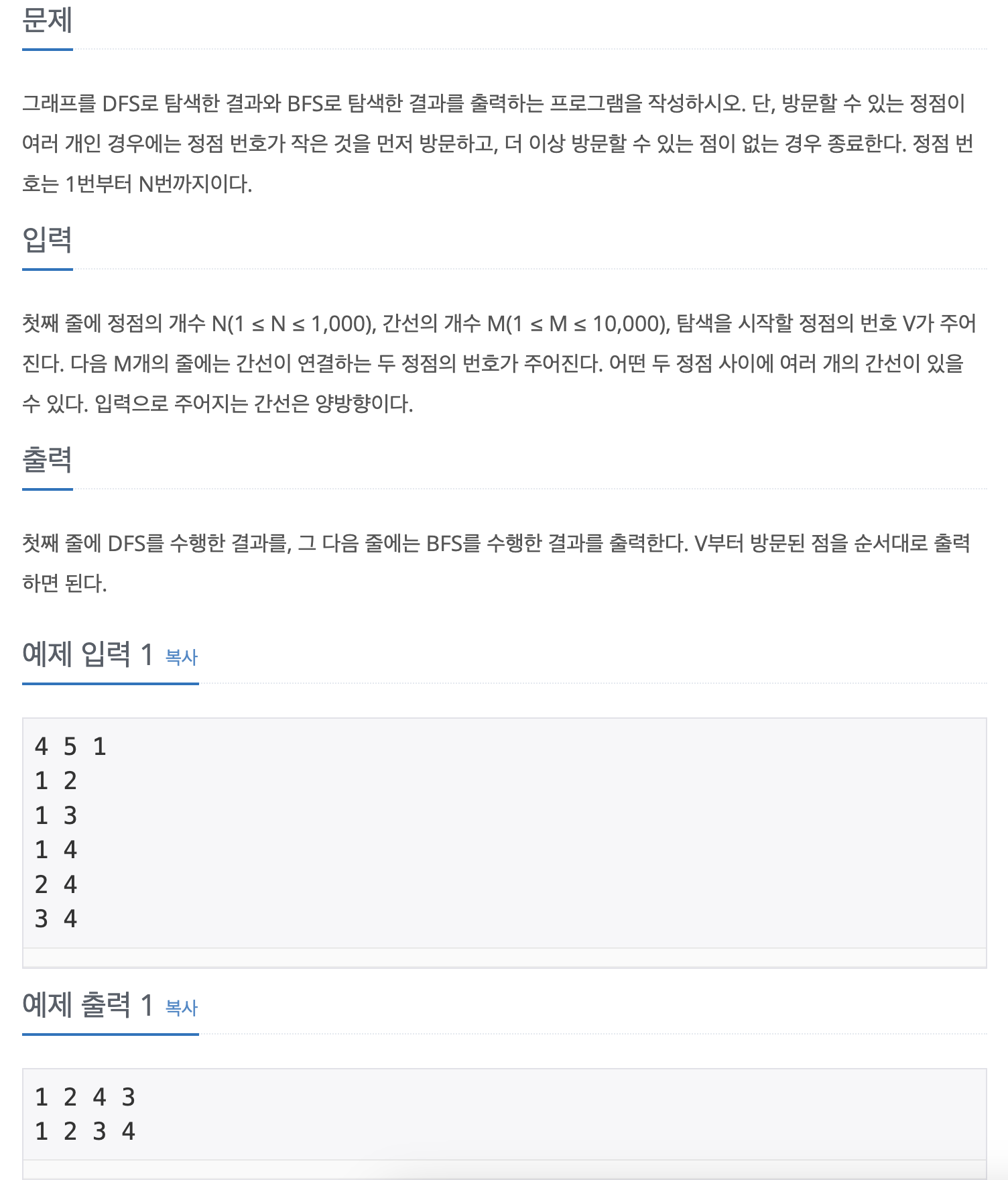
DFS와 BFS의 차이점을 먼저 알아보자. 위의 예제를 그림으로 나타내면 다음과 같다.
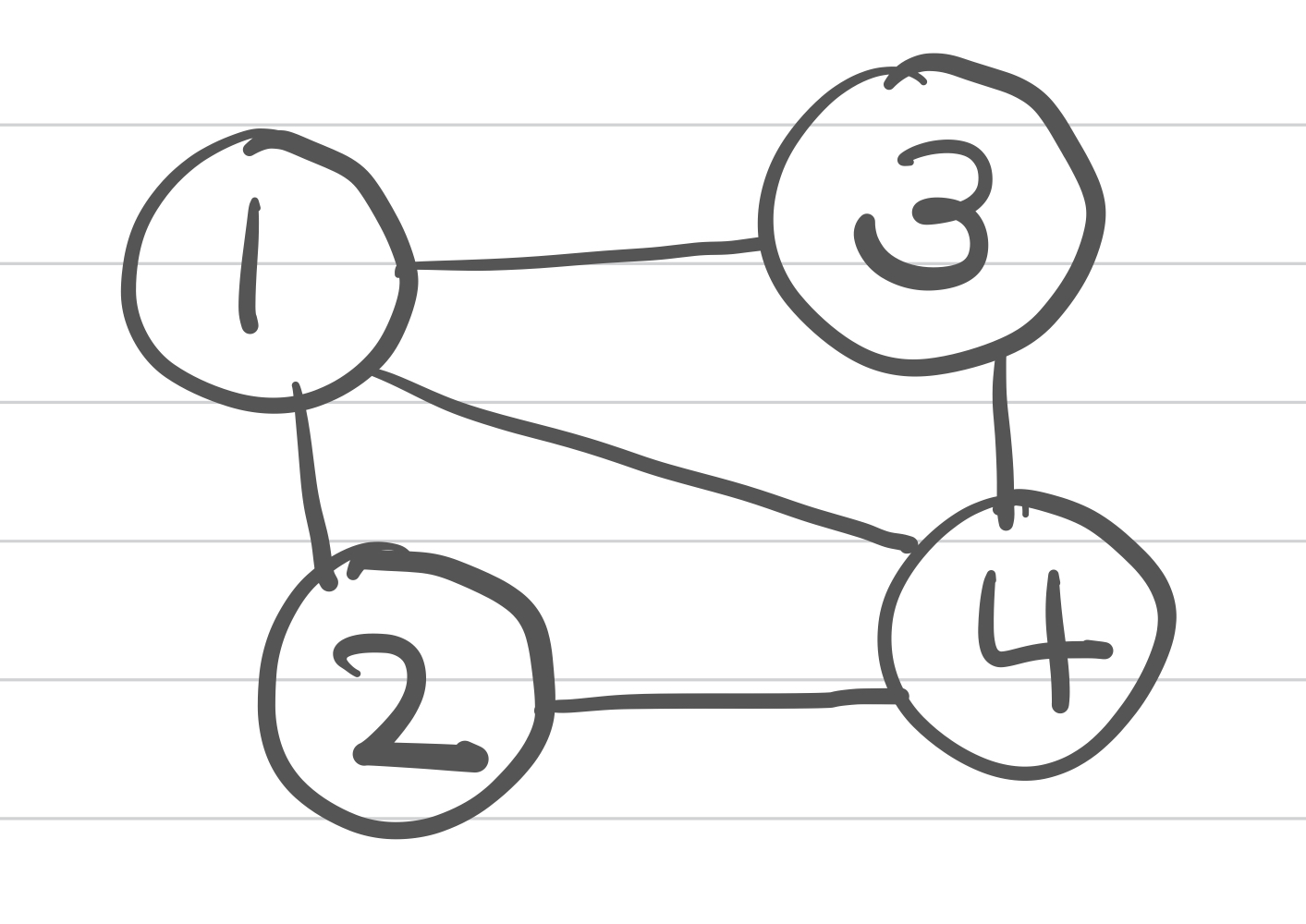
DFS는 끝까지 간다. 보통 재귀를 사용한다.
1에서 시작한다. 1은 2, 3, 4와 연결되어있다. 가장 가까운 친구한테 일단 간다.
제일 먼저 2를 마주친다. 2랑 연결돼있는 애 살펴본다. 1이랑 4가 연결돼있는데, 1은 이미 지나왔네?? 4로 간다.
이제 4랑 연결돼있는 애 살펴본다. 1, 2, 3 연결돼있는데 1, 2는 이미 지나왔네? 3으로 간다.
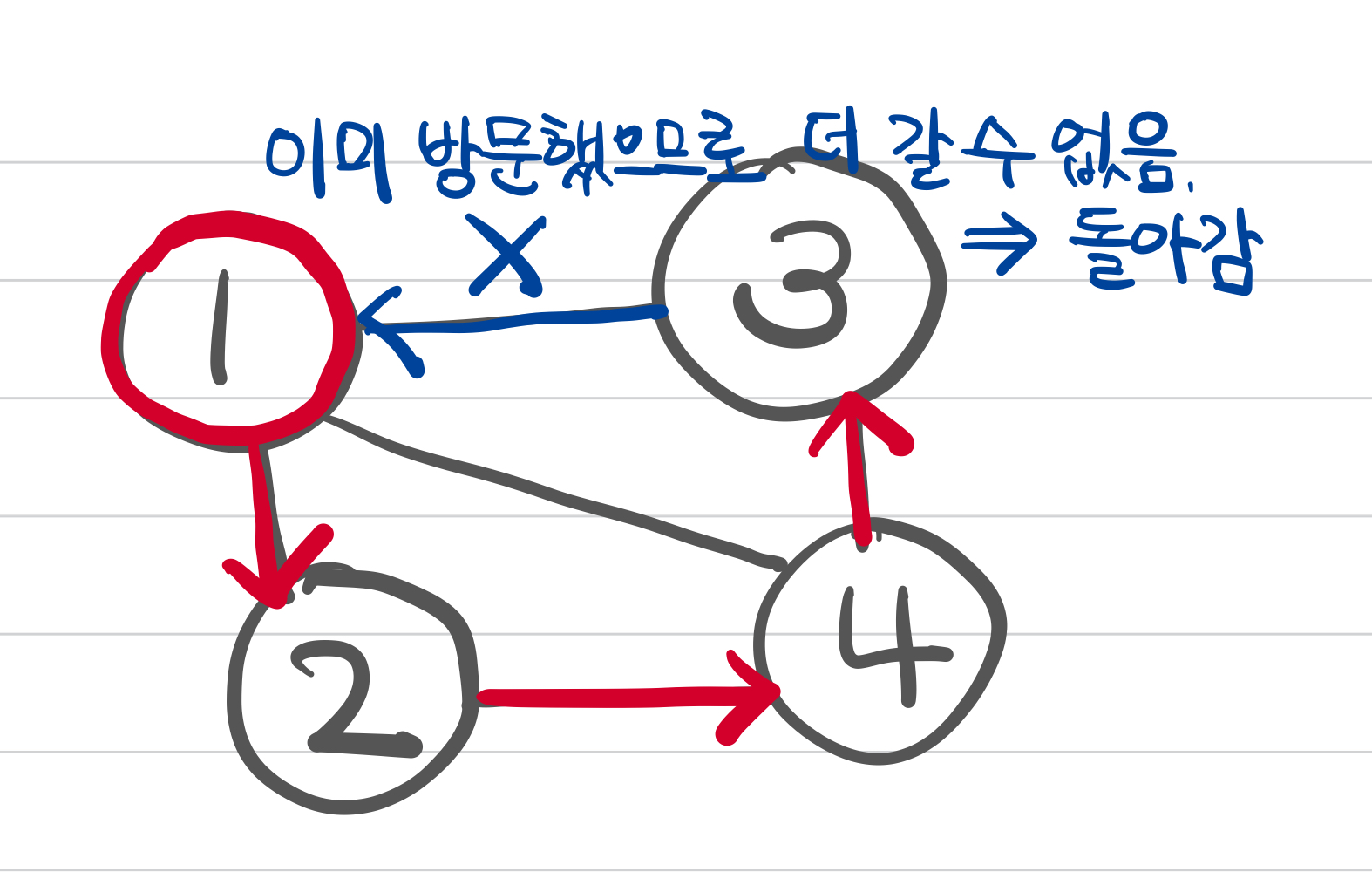
이제 3이랑 연결돼있는 애 살펴본다. 1, 2, 4 연결돼있는데 다 이미 지나온 애들이다. 더 살펴볼 게 없으니까 돌아간다.
4로 돌아왔다. 4랑 연결돼있는 애들도 이미 다 지나왔다. 더 살펴볼 게 없으니까 돌아간다.
2로 돌아왔다. 2랑 연결돼있는 애들도 더 볼 게 없다. 돌아간다.
1로 돌아왔다. 1은 2, 3, 4와 연결되어있다고 했었다. 이제 3으로 가야하는데 3도 이미 들렀고, 4도 이미 들렀다. 더 볼 수 없으므로 탐색을 종료한다.
이게 DFS다. 진행되는 걸 보면 뒷구르기 하면서 봐도 재귀로 구현해야 할 듯 싶다.
BFS는 근처부터 살핀다. 보통 큐를 사용해서 구현한다.
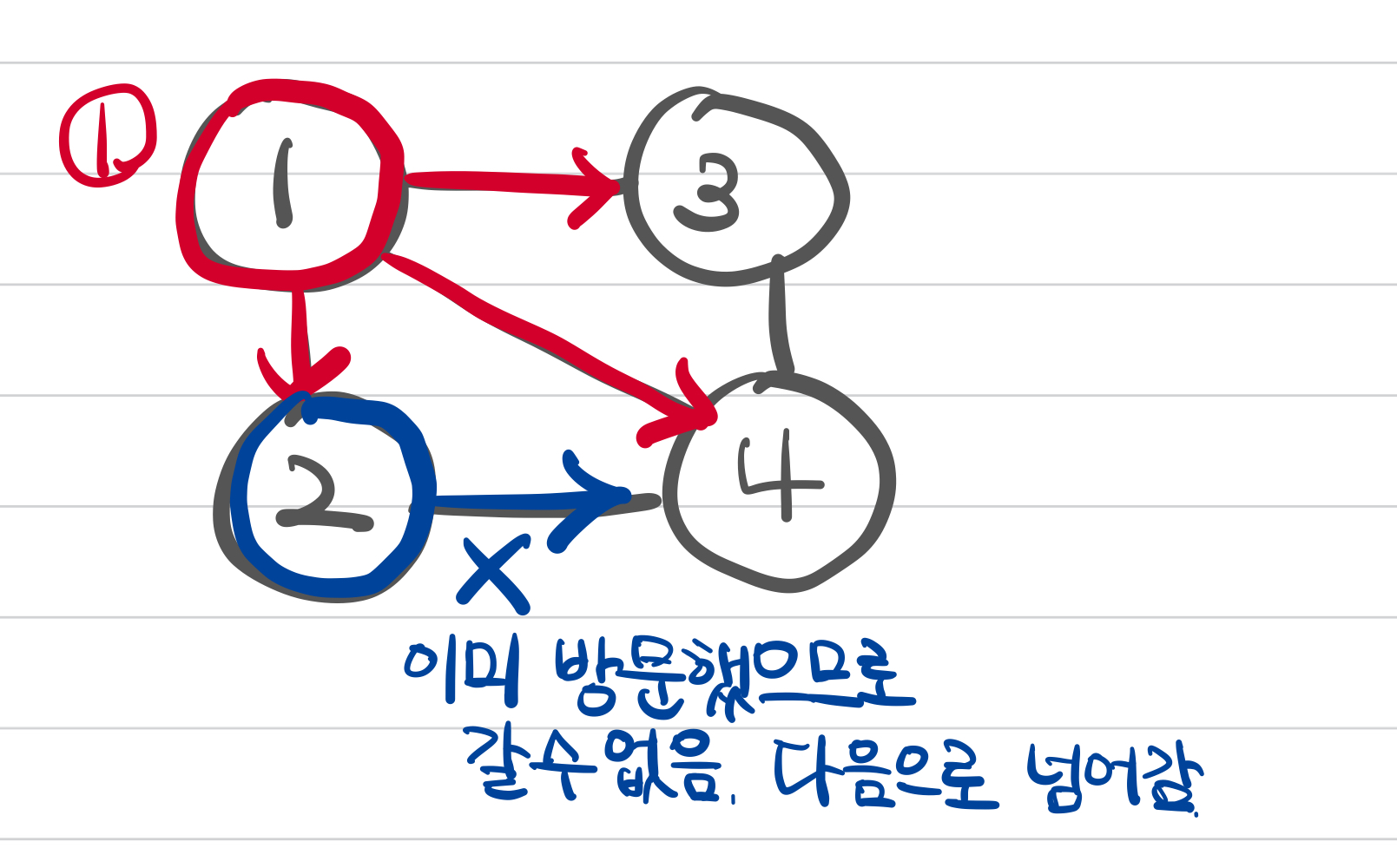
1은 2, 3, 4와 연결되어있다. 큐에 2, 3, 4를 넣어주고 모두 방문처리한다.
큐에서 하나를 꺼낸다. 2가 나왔다. 2와 연결돼있으면서 방문하지 않은 숫자들을 넣어준다. 엥? 없음. 그대로 2 버린다.
하나를 또 꺼낸다. 3이 나왔다. 3과 연결돼있으면서 방문하지 않은 숫자들을 넣어준다. 역시나 없다. 3 버린다.
또 꺼낸다. 4 나왔다. 위랑 똑같다. 뭐 없다!
이제 큐가 텅텅 비었다. BFS 끝!!!! 쏘 쉽다.
* BFS나 DFS나 방문 했는지 안 했는지를 체크해야한다는 것을 기억해두자.
구현하기
1. 데이터 입력 받아 가공하기
입력받은 데이터를 모두 가공해야한다.
4 5 1
1 2
1 3
1 4
2 4
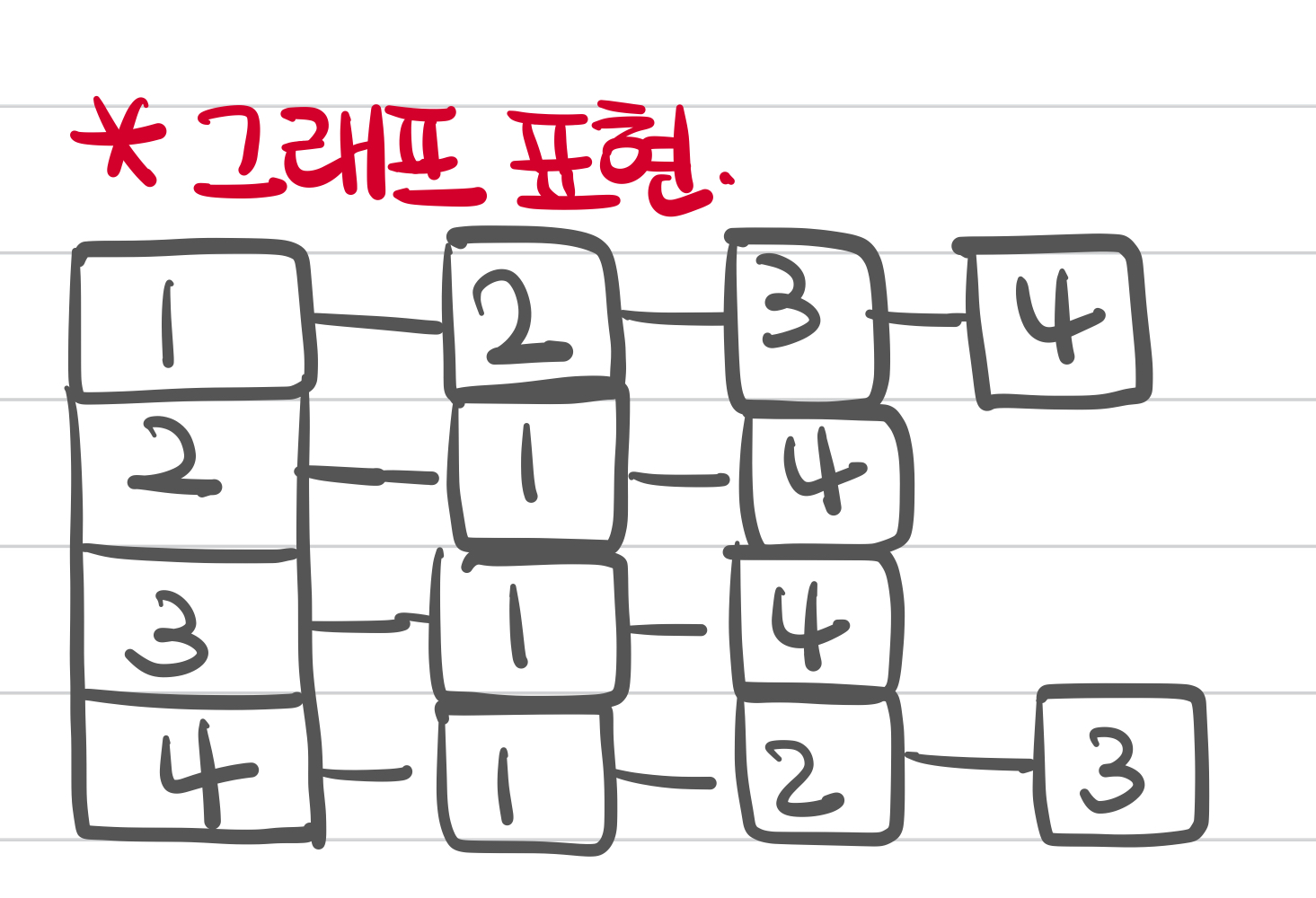
3 4이렇게 중구난방으로 들어온 입력을 어떻게 처리할까? 아래와 같이 해당 인덱스에 어떤 숫자가 연결되어있는지 리스트로 표현할 것이다.
n, m, v = map(int, input().split())
graph = [[] * (n+1) for _ in range(n+1)]
visited = [False] * (n+1) # 방문 했는지 안 했는지 체크할 배열
for _ in range(m):
a, b = map(int, input().split())
graph[a].append(b)
graph[b].append(a)
2. DFS
DFS는 시작 인덱스를 매개변수로 받는다.
def dfs(idx):
visited[idx] = True
dfs_result.append(idx)
for i in range(1, n+1):
if not visited[i] and i in graph[idx]:
dfs(i)매개변수로 받은 인덱스에 방문 처리를 해주고, 미리 만들어둔 dfs_result라는 배열에 방문한 노드의 인덱스를 담아준다.
예를 들어 1번 노드부터 시작한다면 1을 방문처리 한 뒤, 1과 연결되어있으면서 아직 방문하지 않은 노드에 dfs함수를 다시 실행한다.
3. BFS
BFS는 매개변수를 받아서 걜 어찌할 것이 아니므로 매개변수를 받을 필요가 없다.
큐를 만들어서 탐색을 시작할 정점의 번호를 넣어준 뒤, 큐가 빌때까지 하나를 빼고, 걔와 연결되어 있으면서 아직 방문하지 않은 애들을 넣어주는 과정을 반복한다.
def bfs():
q = deque()
visited = [False] * (n+1)
q.append(v)
visited[v] = True
while (len(q) != 0):
idx = q.popleft()
bfs_result.append(idx)
for i in range(1, n+1):
if not visited[i] and i in graph[idx]:
q.append(i)
visited[i] = True
전체 코드
from collections import deque
dfs_result = []
bfs_result = []
n, m, v = map(int, input().split())
graph = [[] * (n+1) for _ in range(n+1)]
visited = [False] * (n+1)
for _ in range(m):
a, b = map(int, input().split())
graph[a].append(b)
graph[b].append(a)
def dfs(idx):
visited[idx] = True
dfs_result.append(idx)
for i in range(1, n+1):
if not visited[i] and i in graph[idx]:
dfs(i)
def bfs():
q = deque()
visited = [False] * (n+1)
q.append(v)
visited[v] = True
while (len(q) != 0):
idx = q.popleft()
bfs_result.append(idx)
for i in range(1, n+1):
if not visited[i] and i in graph[idx]:
q.append(i)
visited[i] = True
dfs(v)
bfs()
print(*dfs_result)
print(*bfs_result)
이렇게 DFS와 BFS 문제를 풀어봤다.
백준 1260번 DFS와 BFS 파이썬 풀이
DFS와 BFS의 차이점을 먼저 알아보자. 위의 예제를 그림으로 나타내면 다음과 같다.
DFS는 끝까지 간다. 보통 재귀를 사용한다.
1에서 시작한다. 1은 2, 3, 4와 연결되어있다. 가장 가까운 친구한테 일단 간다.
제일 먼저 2를 마주친다. 2랑 연결돼있는 애 살펴본다. 1이랑 4가 연결돼있는데, 1은 이미 지나왔네?? 4로 간다.
이제 4랑 연결돼있는 애 살펴본다. 1, 2, 3 연결돼있는데 1, 2는 이미 지나왔네? 3으로 간다.
이제 3이랑 연결돼있는 애 살펴본다. 1, 2, 4 연결돼있는데 다 이미 지나온 애들이다. 더 살펴볼 게 없으니까 돌아간다.
4로 돌아왔다. 4랑 연결돼있는 애들도 이미 다 지나왔다. 더 살펴볼 게 없으니까 돌아간다.
2로 돌아왔다. 2랑 연결돼있는 애들도 더 볼 게 없다. 돌아간다.
1로 돌아왔다. 1은 2, 3, 4와 연결되어있다고 했었다. 이제 3으로 가야하는데 3도 이미 들렀고, 4도 이미 들렀다. 더 볼 수 없으므로 탐색을 종료한다.
이게 DFS다. 진행되는 걸 보면 뒷구르기 하면서 봐도 재귀로 구현해야 할 듯 싶다.
BFS는 근처부터 살핀다. 보통 큐를 사용해서 구현한다.
1은 2, 3, 4와 연결되어있다. 큐에 2, 3, 4를 넣어주고 모두 방문처리한다.
큐에서 하나를 꺼낸다. 2가 나왔다. 2와 연결돼있으면서 방문하지 않은 숫자들을 넣어준다. 엥? 없음. 그대로 2 버린다.
하나를 또 꺼낸다. 3이 나왔다. 3과 연결돼있으면서 방문하지 않은 숫자들을 넣어준다. 역시나 없다. 3 버린다.
또 꺼낸다. 4 나왔다. 위랑 똑같다. 뭐 없다!
이제 큐가 텅텅 비었다. BFS 끝!!!! 쏘 쉽다.
* BFS나 DFS나 방문 했는지 안 했는지를 체크해야한다는 것을 기억해두자.
구현하기
1. 데이터 입력 받아 가공하기
입력받은 데이터를 모두 가공해야한다.
4 5 1
1 2
1 3
1 4
2 4
3 4이렇게 중구난방으로 들어온 입력을 어떻게 처리할까? 아래와 같이 해당 인덱스에 어떤 숫자가 연결되어있는지 리스트로 표현할 것이다.
n, m, v = map(int, input().split())
graph = [[] * (n+1) for _ in range(n+1)]
visited = [False] * (n+1) # 방문 했는지 안 했는지 체크할 배열
for _ in range(m):
a, b = map(int, input().split())
graph[a].append(b)
graph[b].append(a)
2. DFS
DFS는 시작 인덱스를 매개변수로 받는다.
def dfs(idx):
visited[idx] = True
dfs_result.append(idx)
for i in range(1, n+1):
if not visited[i] and i in graph[idx]:
dfs(i)매개변수로 받은 인덱스에 방문 처리를 해주고, 미리 만들어둔 dfs_result라는 배열에 방문한 노드의 인덱스를 담아준다.
예를 들어 1번 노드부터 시작한다면 1을 방문처리 한 뒤, 1과 연결되어있으면서 아직 방문하지 않은 노드에 dfs함수를 다시 실행한다.
3. BFS
BFS는 매개변수를 받아서 걜 어찌할 것이 아니므로 매개변수를 받을 필요가 없다.
큐를 만들어서 탐색을 시작할 정점의 번호를 넣어준 뒤, 큐가 빌때까지 하나를 빼고, 걔와 연결되어 있으면서 아직 방문하지 않은 애들을 넣어주는 과정을 반복한다.
def bfs():
q = deque()
visited = [False] * (n+1)
q.append(v)
visited[v] = True
while (len(q) != 0):
idx = q.popleft()
bfs_result.append(idx)
for i in range(1, n+1):
if not visited[i] and i in graph[idx]:
q.append(i)
visited[i] = True
전체 코드
from collections import deque
dfs_result = []
bfs_result = []
n, m, v = map(int, input().split())
graph = [[] * (n+1) for _ in range(n+1)]
visited = [False] * (n+1)
for _ in range(m):
a, b = map(int, input().split())
graph[a].append(b)
graph[b].append(a)
def dfs(idx):
visited[idx] = True
dfs_result.append(idx)
for i in range(1, n+1):
if not visited[i] and i in graph[idx]:
dfs(i)
def bfs():
q = deque()
visited = [False] * (n+1)
q.append(v)
visited[v] = True
while (len(q) != 0):
idx = q.popleft()
bfs_result.append(idx)
for i in range(1, n+1):
if not visited[i] and i in graph[idx]:
q.append(i)
visited[i] = True
dfs(v)
bfs()
print(*dfs_result)
print(*bfs_result)
이렇게 DFS와 BFS 문제를 풀어봤다.